 La sintesi additiva rappresenta la forma primordiale di generazione sonora. Essa è finalizzata alla creazione/emulazione di timbri di una certa complessità, come quello di un qualsiasi strumento musicale acustico od elettronico. Si fonda sul principio della serie di Fourier la quale prevede che una funzione periodica può essere scomposta in una serie di funzioni sinusoidali fondamentali; nel nostro caso le onde acustiche di un suono.
La sintesi additiva rappresenta la forma primordiale di generazione sonora. Essa è finalizzata alla creazione/emulazione di timbri di una certa complessità, come quello di un qualsiasi strumento musicale acustico od elettronico. Si fonda sul principio della serie di Fourier la quale prevede che una funzione periodica può essere scomposta in una serie di funzioni sinusoidali fondamentali; nel nostro caso le onde acustiche di un suono.
Per semplicità proviamo a pensare ad una casa ed associamola al timbro di una nota di violino per esempio, i singoli mattoni che la compongono saranno le funzioni sinusoidali costituenti il medesimo timbro ottenute sommando tutte queste funzioni. Si ottiene così il suono di partenza e si ricostruisce la casa. Queste funzioni sono delle onde sinusoidali che rappresentano idealmente la parte più piccola scomponibile di un determinato timbro. Per ottenere questo risultato si effettua una serie di lunghi e abbastanza complicati calcoli matematici (trasformata di fourier). Questo procedimento può essere fatto anche in senso inverso,ovvero partendo dalla somma di funzioni sinuosoidali fondamentali, si costruisce una nuova funzione complessa. Avremmo così la “trasformata inversa” il cui acronimo in inglese è FFT (fast Fourier transform).
Per fortuna dei compositori moderni e dei sound design esistono i computer che eseguono in un baleno questi calcoli!
La caratteristica principale di un suono sinusoidale puro è quello di non avere componenti armoniche. Nessuno strumento musicale tradizionale potrebbe generare delle onde di tale specie visto che anche se pizzichiamo un elastico teso o soffiamo aria dentro un tubo produciamo necessariamente un suono composto da una fondamentale più una serie di armonici detti anche” parziali”. In base alla teoria di Fourier, la forma d’onda di un segnale e il suo inviluppo nel tempo possono essere ottenuti matematicamente come combinazione di onde sinusoidali di frequenza multipla di una frequenza fondamentale (F) e di onde sinusoidali parziali di frequenza, e ampiezza diversa che possono crescere, mantenersi e decadere nel tempo modificando il loro inviluppo.
Per ulteriori approfondimenti sulle onde acustiche consiglio la lettura di un precedente articolo del blog su questo argomento
La sintesi additiva si avvale di tutto questo per generare, tramite degli oscillatori, delle forme d’onda come modello ( sinusoidale, triangolare, a dente di sega,quadrata); sommando e modulandole opportunamente è possibile ottenere i più diversi tipi di timbro, emulando in modo realistico, il suono degli strumenti acustici.
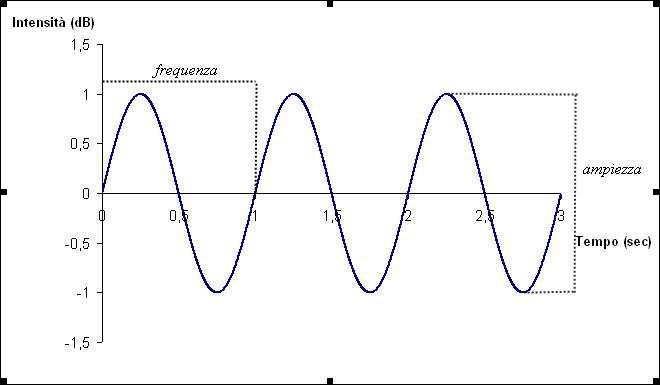
Onde sinusoidali
Le prime tecniche di sintesi additiva utilizzavano naturalmente oscillatori analogici, ma il numero degli oscillatori presenti nei centri di ricerca limitava il campo dell’esplorazione sonora. La creazione di spettri complessi utilizzando un linguaggio per la sintesi del suono è certamente più semplice, ma la costruzione risulta assai lenta e, causa l’enorme mole di dati che richiedeva, ed era solo possibile per applicativi non in tempo reale. Il principale problema è dover indicare per ogni componente armonica, la frequenza, l’ampiezza e l’inviluppo, e per certi timbri complessi (come quelli di emulazione) il numero di sinusoidi impiegate è enormemente alto.Sono questi alcuni dei motivi per cui questo tipo di sintesi è stata nel tempo sostituita da altre tecniche come la modulazione di frequenza.
Tuttavia grazie alla potenza delle moderne cpu e all’utilizzo creativo di linguaggi per
la sintesi come Csound, la sintesi additiva – che resta un eccellente primo approccio didattico alla sintesi del suono – è ancora un campo da esplorare per la ricerca di
timbri complessi e variabili nel tempo.
Non dobbiamo pensare che la sintesi additiva sia qualcosa da associare necessariamente alla musica elettronica visto che la troviamo anche in altre discipline come ad esempio nella pittura e nella fotografia e più in generale nei trattati di ottica.
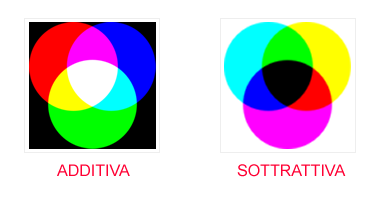
Nella figura a sinistra possiamo notare come i colori possono essere sovrapposti in modo ambivalente (additivo e sottrattivo) per generarne di altri. La similitudine è rafforzata dal fatto che la luce nel suo duplice aspetto quantistico onda-particella altro non è che una serie di onde elettromagnetiche avente una gamma di frequenze peculiari per ogni singola sfumatura di colore, a partire dal rosso fino ad arrivare all’estremo violetto; esattamente come le onde acustiche e le note di una scala musicale. A differenza delle onde acustiche le onde elettromagnetiche non hanno necessità di avere un mezzo di propagazione come l’aria ad esempio, e quindi possono propagarsi anche nel vuoto.
Sorprendentemente il primo strumento musicale che ha utilizzato la sintesi additiva nella propria varietà timbrica non è stato costruito in tempi recenti come facilmente verrebbe da pensare. Dobbiamo andare indietro nel tempo fino ad arrivare al III secolo d.C. Stiamo parlando dell’organo a canne presente nelle chiese e nelle cattedrali di mezzo mondo, protagonista assoluto della musica liturgica.

I diversi registri o voci di un organo a canne vengono prodotti utilizzando gli stessi principi della sintesi additiva anche se l’emissione sonora di ogni singola canna non ha una forma sinusoidale pura(ma si avvicina abbastanza).
Fino ad adesso abbiamo parlato di suoni periodici, ovvero di forme d’onda aventi una frequenza fondamentale (quella propria della nota musicale) più una serie di frequenze parziali relazionabili come multipli della frequenza fondamentale. Questa tipologia di suoni vengono definiti ad intonazione certa in quanto possiamo valutarne in modo univoco l’altezza.La maggior parte degli strumenti musicali producono proprio questo tipo di suoni.
In natura esistono anche suoni non periodici nei quali è impossibile distinguerne l’altezza in modo assoluto: pensiamo al rumore. Questa definizione non ci deve trarre in inganno perchè spesso la distinzione tra suoni periodici /aperiodici non è affatto assoluta a livello percettivo. Infatti, se vediamo lo spettro del suono della campana risulta essere tutt’altro che periodico, ma ne riusciamo ugualmente a percepirne l’intonazione. Possiamo affermare che il confine tra suoni ad intonazione determinata/indeterminata non sia così netto come si credeva in passato.
Queste sono le diverse forme di sintesi additiva
Sintesi additiva di suoni periodici:
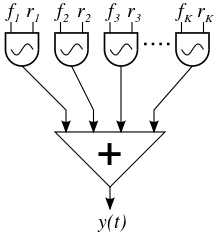
Rappresenta la forma più semplice dove una generica funzione periodica che viene scomposta in una serie di sinusoidi aventi ampiezza e frequenza e fase iniziale derivati dalla trasformata di fourier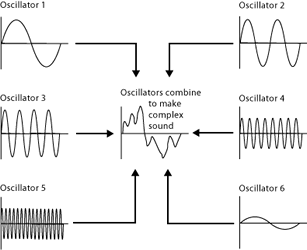 . Si avrà quindi:
. Si avrà quindi: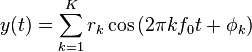
dove l’uscita  è la sintesi di
è la sintesi di  ,
,  e
e  rispettivamente: l’ampiezza, la frequenza e l’offset di fase, rispettivamente, del
rispettivamente: l’ampiezza, la frequenza e l’offset di fase, rispettivamente, del  th armonica parziale di un totale di
th armonica parziale di un totale di  armoniche parziali, ed
armoniche parziali, ed 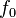 che è la frequenza fondamentale della forma d’onda e la frequenza della nota musicale.
che è la frequenza fondamentale della forma d’onda e la frequenza della nota musicale.
Sintesi additiva di ampiezze dipendenti dal tempo:
Più in generale, l’ampiezza di ogni armonica può essere descritta come una funzione del tempo, 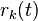 nel qual caso l’uscita di sintesi è:
nel qual caso l’uscita di sintesi è:
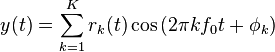
Ogni valore di dovrebbe variare lentamente rispetto alla distanza di frequenza tra sinusoidi adiacenti. La larghezza di banda di dovrebbe essere significativamente inferiore ad .
Sintesi additiva su suono non periodico:
Nel caso generale, la frequenza istantanea di una sinusoide è la derivata (rispetto al tempo) dell’ argomento della funzione seno o coseno. La frequenza è rappresentata sia in hertz, e sia se in forma di velocità angolare , allora questa derivata è moltiplicata per 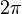 ; Questo nel caso se la parziale è armonica o inarmonica e se la sua frequenza è costante o variabile nel tempo.
; Questo nel caso se la parziale è armonica o inarmonica e se la sua frequenza è costante o variabile nel tempo.
Nella forma più generale, la frequenza di ogni parziale non armonica è una funzione non negativa di tempo,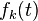 .
.
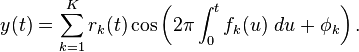
Nel corso del XX° secolo con lo sviluppo dell’elettronica si è assistito alla messa in commercio di sintetizzatori che usavano la sintesi additiva per la generazione timbrica. Eccone alcuni:

Thelarmonium (1906)

Organo Hammond (1935)

ANS (1938)

Fairlight Quasar M8 (1976)

Synclavier II (1979)

Bell Digital Synthesizer 1977
Con il progresso dell’elettronica questo tipo di strumenti sono diventati obsoleti abbastanza presto e sostituiti da altri più performanti. L’unica eccezzione riguarda l’organo Hammond che gode di un’estrema popolarità anche ai nostri giorni. Il mercato propone spesso nuovi modelli di sintetizzatori spesso simili tra loro, in una sorta di competizione consumistica simile a quello che avviene per il mercato dell’iphone e della telefonia in genere.
Il limite di questo tipo di siynt è rappresentato dal fatto di avere dei suoni preimpostati (preset) ,e la possibilità di intervento a fini creativi di modificare o generare nuovi timbri risulta essere molto limitata ed indissolubilmente vincolata dall’hardware.
Viceversa con i sintetizzatori software questi limiti che abbiamo evidenziato spariscono quasi completamente in quanto le prestazioni saranno quelle della CPU e della quantità di memoria RAM disponibile in un computer.
Possiamo distinguere due tipi di sintetizzatori software :
Software di emulazione (virtual instrument) sono dei programmi che simulano un particolare tipo di suono, sia esso un synt oppure uno strumento acustico. Sono molto usati in ambito discografico e possono facilmente essere interfacciati con i sequencer tramite delle librerie denominate VST, RTU,RTAS secondo gli ambienti di sviluppo.
Sintesi tramite linguaggi di programmazione rappresenta il sistema più evoluto della computer music “seria”, anche se è un po’ complessa da utilizzare, in quanto il suo uso richiede una conoscenza interdisciplinare che riguarda oltre la teoria musicale, la fisica acustica e la conoscenza informatica necessaria per scrivere delle righe di codice usando un linguaggio di programmazione. Tali strumenti sono molto spesso ignorati dalla quasi totalità dei musicisti e degli insegnanti che se ne potrebbero avvalere come dei formidabili sussidi didattici partendo dalle fondamenta del suono.
Il linguaggio di programmazione più usato nel mondo della computer music si chiama CSOUND . Esso nasce come strumento di ricerca universitario nei labolratori del MIT media lab presso il Massachusetts Institute of Technology negli Stati Uniti ed usato per ricerche che riguardano svariate discipline. Oltre alle potenzialità illimitate, questo strumento ha il vantaggio di essere totalmente gratuito e liberamente utilizzabile. Con la possibilità, anche per il singolo utente, di sviluppare un suo algoritmo personale. Esiste in rete una comunità molto ampia su csound, con molti forum dove ci si scambia opinioni e consigli. Annualmente si tiene una conferenza ogli anno in un paese diverso. Per il 2015 è prevista dal 2 al 4 Ottobre a San Pietroburgo in Russia.
In conclusione allego il video di un mio studio che si chiama “Abyss” dove ho usato csound per ottenere la sintesi additiva, cercando di mettere in pratica con un esempio sonoro tutti gli argomenti trattati in questo capitolo .